
The National Institute of Information and Communications Technology (NICT) and the University of Tokyo released RaNNC (Rapid Neural Network Connector), automatic parallelization middleware for deep learning, on March 31. This research result was accepted at the IEEE International Parallel and Distributed Processing Symposium (IPDPS), one of the field's top international conferences, and presented on May 20. In recent years, the size of neural networks for deep learning has been rapidly increasing. As a result, developers are often required to manually rewrite complex neural network definitions to partition them and ensure that the networks can fit into a graphics processing unit (GPU) memory. In contrast, RaNNC can automatically partition neural networks and parallelize training using multiple GPUs. RaNNC is claimed to be the first software that can automatically partition a neural network without having to rewrite its definitions.
The source code of RaNNC is available on GitHub, an open-source software repository. It is licensed under an MIT license, which has few restrictions. Therefore, users can use RaNNC for free, even for commercial purposes. Hence, RaNNC should enable various organizations developing deep learning systems to train large-scale neural networks and to boost development of various technologies, products, and services.
In deep learning, recent research has revealed that large-scale neural networks bring significant performance improvements. As a result, neural networks of unprecedented scales have been proposed around the world. For deep learning, it is common to use GPUs to accelerate computation. Thus, efficient parallel computation using of a large number of GPUs is important to train large-scale neural networks. However, existing software to train large-scale neural networks require significant rewriting of complex neural network definitions to partition the neural networks and fit them into GPU memory. In addition, such rewriting involves high-level expertise and large development costs, which has so far limited the number of organizations that can carry out training of large-scale neural networks.
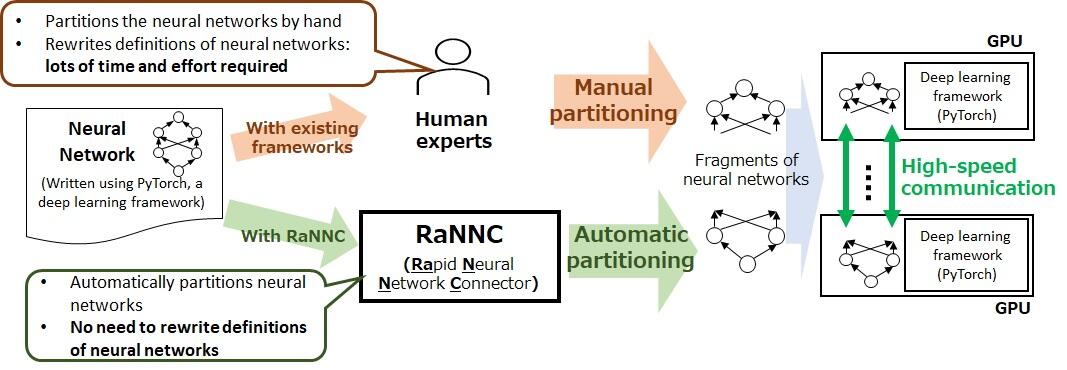
Given the definition of an existing neural network written for PyTorch, a de facto standard deep learning software, RaNNC can automatically partition the neural network to fit it into the memory of each available GPU while optimizing the training speed using multiple GPUs. Therefore, developers do not need to rewrite the neural network definitions for partitioning, which makes training of large-scale neural networks much easier. Also, existing software for large-scale neural network training, such as Megatron-LM, can only be applied to certain types of neural networks such as BERT, which is a neural network developed by Google. In contrast, RaNNC has essentially no limitations on the type of neural network it can train.
Experiments using NICT's computer environment showed that RaNNC can train neural networks approximately five times larger than Megatron-LM while achieving almost the same training speed for neural networks small enough that both RaNNC and Megatron-LM could train them. Data-driven Intelligent System Research Center at NICT has developed various systems including WISDOM X (a large-scale Web information analysis system) and MICSUS (Multimodal Interactive Care SUpport System). Some of these systems have been released to the public or licensed to commercial companies. These systems use various neural networks, and their performance is expected to further improve through using large-scale neural networks trained with RaNNC.
This article has been translated by JST with permission from The Science News Ltd.(https://sci-news.co.jp/). Unauthorized reproduction of the article and photographs is prohibited.