
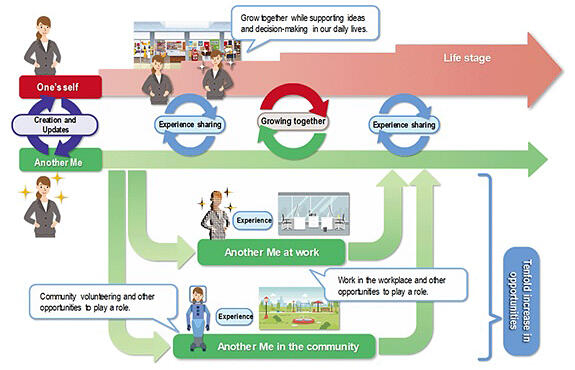
NTT aims to increase opportunities and foster self-growth through activities and interactions that go beyond the constraints of the physical world using Digital Twin Computing (DTC), an initiative advocated by the company. The objective is to realize "Another Me" − i.e. an AI agent serving as an alter ego that acts as, and shares experiences with, that person. The NTT version of the LLM (large-scale language model) named "tsuzumi" has been extended as a new technology crucial for achieving this vision. On January 17, 2024, the company announced the development of a personalized dialogue reproduction technology that generates dialogue with a small amount of data, reflecting the characteristics of an individual's unique tone of voice and speech content. Simultaneously, they have also developed Zero/Few-shot speech synthesis technology, which synthesizes a voice that reflects an individual's tone from a small amount of audio data. A prototype of a digital alter ego utilizing these new technologies was reproduced, displayed, and introduced at docomo Open House '24, held from January 17th to 18th, 2024.
Provided by NTT
Traditionally, reproducing a digital alter ego with learned personal characteristics has required the availability of large amounts of data about the individual. In this research, DTC has made it possible to reproduce a digital alter ego with a small amount of data, allowing anyone to easily have their own alter ego in the digital space. To put the results of this research to practical use, NTT plans to conduct public demonstrations featuring digital alter egos capable of communicating with people and engaging in community activities, representing individuals on behalf of themselves.
Current digital twin technology maps individual objects in the real world onto cyberspace as a digital twin, analyzes and predicts them, and reflects the results back into the physical world by reverse mapping. By contrast, the DTC proposed by NTT goes beyond the current digital twin concept. It involves making calculations by freely combining digital twins of various industries, things, and individuals. The idea is to enable further future predictions by means of high precision reproduction of combinations that could not be managed in an integrated manner, such as combinations of people and automobiles within a city. However, this requires a digital alter ego capable of acting as a proxy for the individual with a distinct personality in society. NTT is developing "Another Me" as such a digital alter ego.
"Another Me" is an alter ego of an individual with the ability to communicate like that individual does. Everyone is assumed to have their own digital alter ego. However, LLM can be applied to dialogue technology, generating natural human conversations, including chats and discussions, by learning from a large amount of data collected from various dialogues. However, in previous research on dialogue technology, LLMs were re-trained and fine-tuned using large amounts of data about individuals to replicate individuality. As a result, the cost was high, and it could not be used to recreate the digital alter ego envisioned by ''Another Me'' for everyone.
Therefore, this time, they combined adapter technology, which is a method for efficiently learning LLM with a relatively small amount of data, with persona dialogue technology, which adds persona (personality) functions to LLM. Through this combination, they have developed a personalized reproduction dialogue technology, an extension of NTT's version of LLM "tsuzumi," that generates dialogue from a small amount of dialogue data, reflecting an individual's tone of voice and speech content characteristics.
Moreover, for the voice used by the alter ego, conventional technology requires several dozen minutes of voice data for each speaker to replicate their tone of voice. Since that would be too expensive, they developed a new technology that allows the generation of high-quality and diverse expressions using a smaller amount of voice data. Zero-shot voice synthesis technology can capture the person's tone with just a few seconds of voice data, while Few-shot voice synthesis technology achieves the same with a few minutes to ten minutes of voice data.
This article has been translated by JST with permission from The Science News Ltd. (https://sci-news.co.jp/). Unauthorized reproduction of the article and photographs is prohibited.