User interface (UI) technologies that make computer systems easier to use as well as machine−human interactions have become increasingly important in the current era of AI and machine learning revolution. Professor Takeo Igarashi from the Graduate School of Information Science and Technology, the University of Tokyo, has been developing a series of advanced AI application technologies, such as a technology to instantly convert images in the mind into three-dimensional computer graphics (3DCG), an animation generation technology, a virtual try-on technology, and a "co-occurrence bias" removal technology to prevent misjudgments by AI. He continues to pursue a better relationship between humans and machines.

Users created their own 3D models and amazed creators around the world
A two-dimensional (2D) sketch of a creative character drawn on a screen instantly transforms into a three-dimensional (3D) computer graphics (CG) image with the audio of a stuffed toy. Professor Takeo Igarashi from the Graduate School of Information Science and Technology at the University of Tokyo, invented such a system more than 24 years ago. In 1996, while enrolled in a doctoral program at the University of Tokyo, Igarashi experienced the most profound impact in his life when he visited Brown University in the United States for an internship, where he saw CG technology that could create hand-drawn illustrations from 3D models expressed as polyhedral objects.
"I had always been interested in 3DCG and had been exploring a system to transform a pen-drawn illustration into a three-dimensional image. The moment I saw CG technology at Brown University, I had a flash of inspiration: 'Let's try the opposite of this.'" It was the year after the release of "Toy Story," the world's first full-length 3DCG animation film. This was also a time when the world was beginning to pay attention to 3DCG. After this, Igarashi chose a 3D modeling system for 2D sketches as his research subject. In 1999, he presented a paper on a 3D modeling technology for 2D sketches, named "Teddy" at "SIGGRAPH 99," a world-class conference on CG (Fig. 1).
Fig. 1: 3DCG image created by "Teddy"

This system caused a sensation that stunned researchers and creators worldwide as soon as it was released. Conventional 3DCG was commonly recognized as something that could be created exclusively by engineers and creators with specialized skills, and users could only make use of the end results. Teddy hauled 3DCG creation out of the hands of professionals and into the hands of amateurs, creating a world where 3D models can be easily generated and edited without requiring special training.
Based on this achievement, Igarashi also succeeded in developing a "spatial keyframing method." This method allows for the smooth movement of sketched creative 3D characters to generate real-time animation on the screen with very few operations. This technology was so well received that even he himself was surprised, and part of it was commercialized through products such as "Shade," a popular PC software used for 3D modeling. Similar products such as Microsoft's "Paint 3D" and Adobe's Photoshop software have also been made available in the marketplace.
Visualization customized for individual body shape and pose: A "virtual fitting method" developed over the course of three years
However, the goal of Igarashi's research is not limited to improving the efficiency of 3D modeling and the creation of computer graphics. "To make computer systems easier to use, we must also consider how humans and systems interact. My ongoing research topic is how to convey images in human minds to the system and how to leverage the system's output results."
During his undergraduate years, he gained experience through internships at Xerox Palo Alto Research Center, Microsoft Research, and Carnegie Mellon University in the United States. He also undertook internships at companies such as Nippon Telegraph and Telephone (NTT) and Ricoh in Japan. However, he felt that in many cases, private companies were required to acquire patent protections for their developed technologies, and commercialization was limited only to those specific companies. Nonetheless, he chose to pursue his research at the university because he believed that the university offers a higher degree of freedom in research and a higher potential for expanding the utilization and practical application of technology. As he pursued UI and interaction technologies as a researcher, the relationship between AI, machine learning, and humans has become an important topic.
In 2017, Dr. Igarashi was selected for JST CREST for "Interaction for understanding and controlling data-driven intelligent data systems" project. In addition to topics common among AI technologies, such as data generation and learning processes, CREST has developed and presented several individual applications that visualize what is happening in the system when using the learned results. This allows users to intervene appropriately and obtain the desired results.
Three of the most remarkable achievements are introduced below:
The first achievement is an advanced "virtual try-on method" that accommodates body shapes and postures. Systems that allow users to virtually try clothes on a screen are already in practical use. However, it is difficult to generate realistic virtual fitting images instantly using systems that use simple 3DCG or generic deep learning models. In response to this, Igarashi and his team prepared a mannequin robot that could freely change its body shapes and postures.
They dressed the mannequin robot and had it mimic various poses of humans with various body shapes and captured tens of thousands of photographs. Through deep learning based on the data obtained from these photographs, they could successfully visualize in detail how the garment would wrinkle depending on the body shape and pose, as well as how the garment would fit each body part. In addition to virtual try-on simulations designed for an online store, they are also conducting demonstrations to change outfits for attendees of online conference videos. (Fig. 2)
Fig. 2: Use of images for the virtual try-on system

AI and machine learning are often associated with data and algorithms, but the generation of specific images also requires an element of "Monozukuri (craftsmanship)" and patience in creating data. "Although the program may be completed in a short period of time, the learning process would take a long time. Even if the images could be captured in two hours, the learning process would take two nights. If a mistake is made and the process started over, the system would take another two nights to learn again. This is a common problem in machine learning, but in the case of the virtual try-on method, it took about three years from conception to realization," said Igarashi, describing the difficulties involved in its development.
Road-crossing decision by looking at the "eyes" of a vehicle - Reduced traffic risks of automated driving
Research on UI and interaction is not solely related to technology on the system side. To realize better interactions between humans and machines, Igarashi and his team also explored a system to visualize AI decisions that could help humans understand them. This is the second achievement, a self-driving vehicle with "eyes" (Gazing car) This self-driving vehicle indicates the direction in which the AI driver is paying attention to, along with the angle of its "eyes" attached to the front of a vehicle. In the experiment, they studied road-crossing decisions of pedestrians who saw the indication of the direction of the "eyes."
Through these pedestrian crossing experiments, they observed that pedestrians tended to determine that it was safe to cross the road when the eyes of the self-driving vehicle were directed toward them, interpreting that "we are being noticed." Conversely, when the eyes were directed in another direction, pedestrians tended to perceive the situation as dangerous, interpreting that "the vehicle is not aware of our presence." Through this, it was shown that by indicating the direction of the AI's attention through the orientation of the 'eyeballs', pedestrians could often exhibit appropriate danger avoidance behavior, which is useful for reducing traffic risks. It was also found that there were significant gender differences in danger avoidance behavior (Fig. 3).
Fig. 3: Investigating pedestrians' reactions to a self-driving vehicle with "eyes" in experiments.
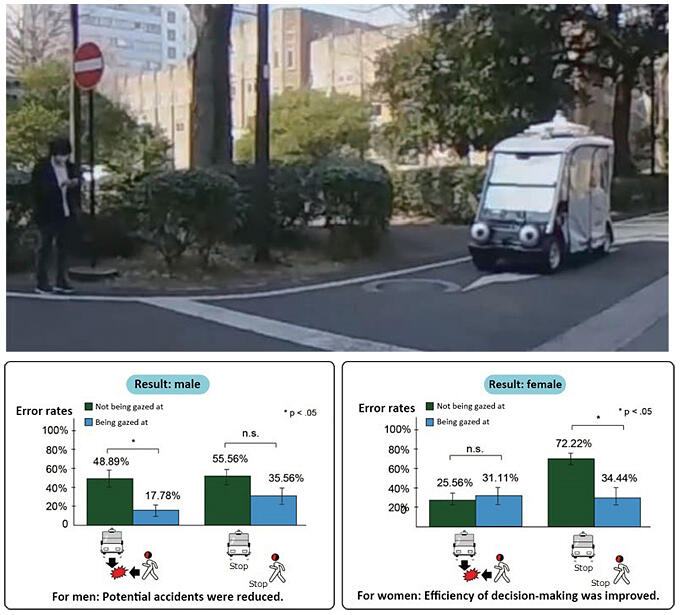
Igarashi summarized this as "This research was conducted under the assumption that in the future, AI integrated into self-driving vehicles will be linked to eye movements, and the gaze itself will directly represent the status of the AI." In the future, when self-driving vehicles will be driving on public roads, the topic of how to convey the decision of self-driving vehicles to pedestrians so that they can safely avoid potential dangers will gain increasing importance. Research on human interaction is essential even in other AI applications.
Prevents AI from learning incorrectly: Guidance to the right path with a single click
The third achievement is the development of technology to prevent AI from learning incorrectly. Machine learning may require appropriate human intervention in the learning process to ensure that incorrect final decisions are not made. For example, to learn the shape of a ship from an image of the ship floating in the sea, the attention of the system should be focused on the ship itself rather than elements in the image such as "waves" or "coasts." Moreover, to learn "lipstick" from a large number of face images, the attention should be focused on the lips. However, in reality, "people who wear heavy makeup around their eyes often wear lipstick." Therefore, the eye area may be targeted for learning.
This could lead to errors in the output of machine learning. Such a problem is called "co-occurrence bias," and preventing it has become one of the major challenges in machine learning. To remove the influence of co-occurrence bias, it is necessary to either modify and reorganize the original data appropriately or to provide annotations of the regions directly specified by the user, thereby indicating which regions should be learned. However, reorganizing the data set also incurs significant costs, including pixel-by-pixel annotations for regions specified by the users.
To reduce the time and effort involved, Igarashi and his team have developed a technology that enables AI to recognize specific regions through a single mouse click on the image display screen. In the example of the ship mentioned above, when clicking the left mouse button on a ship image, the visible part of the ship will be a target to be identified. By contrast, when clicking the right mouse button on the surrounding water, it will be removed from the target to be identified. This approach significantly reduces the training time and cost of machine learning as well as the human effort involved in annotations. (Fig. 4)
Fig. 4: Image of single-click annotation technology to remove AI co-occurrence bias.

An approach in which a human adjusts and teaches where to pay attention is referred to as "attention guidance." The key to this achievement is that the process of directing the AI's attention has become remarkably simple. Igarashi explained, "By combining the active learning methods we developed at the same time, we were able to demonstrate that the time required for attention guidance is reduced by 27% and the accuracy of learning is significantly improved."
Struggling to squeeze out new ideas − It is crucial to learn, prototype, and think
In addition to applications, Igarashi continues his research to realize a number of other ideas, such as a technology that allows users to select from a variety of images presented by AI to generate images that closely resemble the images in their minds as well as a technology that enables complex and diverse image adjustments using only a single slider. The most difficult phase is to produce ideas that no one else has come up with yet. However, once this phase is overcome, he said that the creation of applications can proceed, utilizing and applying existing technologies.
"For new ideas, it is essential to read a lot of research papers, to prototype ideas, and think hard." The background for Dr. Igarashi's research and development is based on the ideal of UI and interaction, in which humans and computers share data with each other to create better results. This ideal is linked to CREST's goal of "Creation and development of core technologies interfacing human and information environments."
As "ChatGPT," a generative AI powered by a large-scale language model released by OpenAI in the United States in November 2022, has attracted worldwide attention, it is often said that we are currently in a transformative period in the history of AI utilization. Charting a course for the future, he said, "We are still exploring what we can do with what we've done, but the fundamental idea remains the same. We would like to continue to address the challenge of enabling users to operate the system as they wish, without requiring specialized knowledge."
(Article: Masahiro Dohi, Photography: Akihiro Ito)
